
In modern software architecture where applications are distributed on the cloud we will often see challenges in performance. Traditionally we used to build monolithic applications that communicated within the process and shared everything in memory. We would host these applications on physical hardware and co located databases with them. If there was performance issues the normal reaction would be to improve the hardware.
Now with applications on the cloud there is a lot more communication between process over the network and we need to design our code in a different way but also apply trick and techniques to ensure that our application performs just like the monolith did.
One of these techniques is Caching. Often I get the impression from others that caching will magically solve our performance problems and it’s quick and easy to add. I actually think it’s a lot harder to get it right and have often seen caching cause more harm than good.
Common mistakes tend to involve
- Using the Cache as a database. When you are dealing with a large amount of data it can be difficult for a developer to cache the same object multiple times. Query logic is then built in and before you know it you have a NoSQL database and not a cache, making the code more complex and the need to support 2 databases.
- Using the Cache as a Service. With distributed caches it might be tempting to have multiple services call the same cache as it seems quicker. What is the harm of a service that needs that data just querying the cache for read purposes? Before you know it you have coupled the services together and have undone everything you were trying to accomplished with microservice design.
What is the problem we are trying to solve?
Let’s look at the basic layout of our application
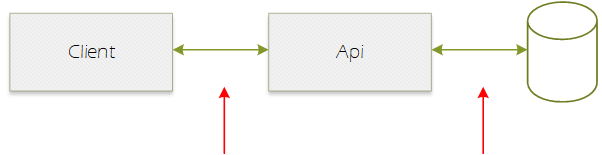
We want to reduce the amount of communication and serialization between these these different parts of our application.
- We want to reduce the amount of times our client (JavaScript or maybe another Api) requests data that hasn’t changed
- Reduce the amount of times our Api requests data from our database
So what we end up with is caching on the Client and the Api.

However the Api owns the Domain data and must be responsible for
- Communicating whether the data can be cached by client and the conditions it may cache under
- The lifecycle of the data and managing updates to the cache with events involving creating and updating.
This seems obvious when it comes to an in memory database but when we start to use distributed caches then the temptation comes to abuse this.
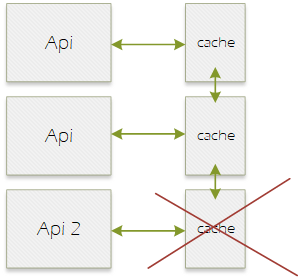
The distributed cache should be used to keep service instances in sync. If using load balancing and you are scaling out horizontally then you want to have the same behaviour from each instance of your service. If you add an item to one service then the other instances needs to reflect that change.
In this example Api 2 would have it’s own cache of the identical data. It may seem wasteful but there are always trade-offs
Caching is expensive. . . For increased performance we need to spend on memory. If we try to use a cache like a database or a service in our design then we start to cause issues with coupling, increasing dependencies and preventing our application from being delivered using CI/CD.
I think it’s important to have a design and strategy around caching and invest time in it. In my next post I will look at how to apply these principals to my .Net Api.